





基于FPGA的关键词识别系统实现(一)
出处:电子技术网 发布于:2013-06-08 11:15:28
摘要:随着微电子技术的高速发展,基于片上系统SOC 的关键词识别系统的研究已成为当前语音处理领域的研究热点和难点.运用Xilinx 公司ViterxII Pro 开发板作为硬件平台,结合ISE10.1 集成开发环境,完成了语音帧输出.MFCC.VQ和HMM等子模块的设计;提出了一种语音帧压缩模块架构,有效实现了语音帧信息到VQ 标号序列的压缩,实现了由语音帧压缩模块和HMM模块构建的FPGA关键词识别系统.仿真实验结果表明,该系统具有较高的识别率和实时性,为关键词识别系统的FPGA硬件电路的实现研究提供了实例.
1 引言
关键词识别是指检测连续语音流中是否包含有特定的词并识别出该词,其在人机交互.国防监听.工业控制.交通管理和产品证件防伪等领域都有着广泛应用.目前关键词识别的应用主要基于通用计算机,该类系统很难满足市场对实际产品便携性.节能性.实时性和低成本等方面的要求.随着数字电子和集成电路等技术的飞速,基于片上系统SOC 的关键词识别已成为当前语音处理领域的研究热点.
本文在MATLAB 对关键词识别系统可行性进行仿真的基础上,采用Xilinx 公司的ViterxII Pro 开发板作为硬件平台,使用集成开发环境ISE10.1 进行设计,结合FPGA 逻辑设计流程和常用设计技巧,实现了基于FPGA 的关键词识别系统.在系统设计实现中,提出了集语音帧输出.MFCC 特征参数提取和VQ矢量量化技术于一体的帧压缩模块的架构,有效实现了语音帧信息到VQ 标号序列的压缩;同时提出了以遍历搜索失真测度模块为的VQ 模块和并行全搜索的HMM模块架构,完成了高速的搜索匹配.
2 关键词识别原理概述
关键词识别的实现包括训练过程和识别过程.训练过程通过处理大量的训练样本不断优化各关键词的模型参数,直到该模型参数能够完整并有效地表征该关键词特征信息.识别过程将提取到的待识别语音关键词的特征信息与各关键词的模型分别进行匹配,通过的得分判断是否属于给定关键词,并给出识别结果.
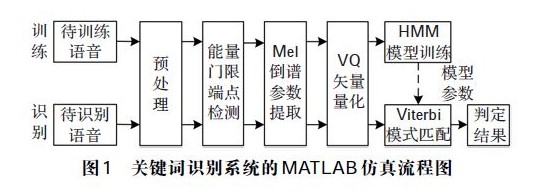
本文首先通过MATLAB 对设计的关键词识别原理进行了可行性研究,其仿真流程框图如图1 所示.
3 系统总体结构方案设计
按照关键词识别系统的工作流程,本文设计的基于FPGA 的关键词识别系统架构如图2 所示.系统主要包含五个组成模块:端点检测.特征参数提取.矢量量化.HMM识别和状态机模块.

为了实现端点检测模块,本文提出了以端点检测模块为的帧输出模块,通过帧输出模块检测到有效帧信息并且控制语音帧的输出,供后续模块处理.由于匹配模板无需设计专用于训练的硬件电路模块,因此VQ 码书和HMM模型参数可以在MATLAB 中实现并进行数据格式转换后,存储在FPGA的ROM中,供编码和识别时使用.
图2 中ROM1 用于存储VQ码书参数,ROM2 用于存储关键词HMM模型参数.语音信号经预处理后存储在RAM中,此后调用帧输出模块对语音段进行端点检测,得到有效语音段的初始帧编号和结尾帧编号,并且计算出有效帧数.获取有效语音帧后,提取有效语音帧并输入MFCC模块进行特征参数提取,其结果直接输入VQ 模块进行矢量量化,并终产生矢量量化编号.
由于待测语音包含多帧语音信息,需要循环执行帧输出.MFCC 特征提取和VQ 矢量量化.本文提出了帧压缩模块的架构,将帧输出.MFCC 和VQ 三个模块进行组合,采用流水线操作循环执行帧压缩流程,并通过计数器记录已经完成处理的帧数,直到所有语音帧的VQ 量化序列产生,将编号序列输入HMM模块进行模式匹配,并通过LED输出显示的识别结果.
4 关键技术及其实现
4.1 FPGA数据的浮点数表示
在FPGA 设计中综合考虑速度与面积的均衡,常采用Q 格式法或者浮点数表示法.为了保证数据具有做够的,本文采用了IEEE754 标准的浮点数表示法,其标准规定是基数为2,阶码e 用移码表示,尾数f 用缺省位1 的原码表示.以单浮点数为例,其格式如图3 所示.

基于IEEE754 标准的浮点数格式表示的实数具有范围广和高的优点,有利于提高系统识别率.
4.2 帧输出模块设计与实现
帧输出模块中主要的是端点检测模块.此模块的终目是为了获得有效的语音帧,而在获得待测语音帧的初始帧编号.结尾帧编号以及有效语音帧数后,还需要编写相应的电路模块,将数据分帧提取出来的数据输入到下一模块.本文的端点检测模块采用基于能量门限的算法,其根据有效音节与无效音节之间的短时能量区别实现端点检测.计算公式如下:

式中L 代表帧长.
据此,本文设计了状态控制模块FSM和地址产生模块Adr_gen,并将各模块有机连接成一个整体,实现了帧数据的输出.在端点检测模块中,帧短时能量计算中的求和运算采用组合逻辑浮点加法器.
采用ISE 集成的综合工具XST 对帧输出模块进行综合,其结果如表1 所示.

帧输出模块(Frame_output)的时序延迟约为16.962 ns,该时序延迟主要来源于组合逻辑.
4.3 MFCC模块设计与实现
本文特征提取采用Mel 频率倒谱系数MFCC 的方法,MFCC特征参数提取流程如图4 所示.

首先对经过预处理后的语音帧x(n) 通过快速傅里叶变换FFT 得到X (k) ,然后采用式(2)所示的离散功率谱函数求取离散功率谱参数.
$2..
根据临界带宽理论,将离散功率谱通过如图5 所示的24 组不同频带的Mel 滤波器进行滤波.每个滤波器频带总能量算法按式(3)求解:

从图5 中可以看出,每个频带内的带宽不同,这是因为滤波器组的带宽并非呈线性分布,而是呈对数分布的.因此较为准确地描述了人耳的听觉特性.

求解对数功率谱,并通过离散余弦变换DCT 得到的MFCC参数,计算过程如式(4)所示:

从表2 分析得知,由于MFCC 模块的实现采用了大量的模块复用技术,使得逻辑资源的占用得到了有效控制.
而模块延迟主要是由部分组合逻辑引起的.
4.4 VQ模块设计与实现
VQ 矢量量化是一种高效的数据压缩编码技术,是指将一组标量组合在一起进行整体量化,是标量量化的一种推广.研究证明在语音识别理论中引入矢量量化,对系统性能的影响非常微小,却能够有效去除大量冗余信息,实现高效的数据压缩.在VQ 矢量量化实现中,主要设计包括码书的生成和失真测度的计算.
本文采用LBG 算法迭代生成码书.码书的生成过程,如图6 所示.

根据矢量量化技术的应用和所选的参数类型,可以选择不同的失真测度.本文选择了平方失真测度,如式(5)所示:

在XST对矢量量化模块VQ进行综合,结果如表3所示.

从表3 可以看出,VQ 模块占用逻辑资源较少,具有较高的工作频率,其逻辑资源和系统延迟主要源于失真测度模块.
4.5 HMM关键词识别模块设计与实现
在HMM 模块的设计中,主要包含两部分设计:其一是基于Baum-Welch 算法的HMM 模板训练;其二是基于Viterbi 算法的模式匹配.从算法上来说,HMM模板训练采用的Baum-Welch 算法比较复杂,但由于无需硬件电路,在识别过程中直接使用即可,所以该部分采用MATLAB实现,并将结果进行编码后存储在只读存储器中.关键难点在于硬件电路中的Viterbi 算法实现.
Viterbi 算法是为了搜索状态链而引入的.设置初始状态后,与所有的HMM模型分别进行匹配,即搜索状态路径,记录下状态链以及幸存概率.本文设计了S1~S6 六个状态,结合HMM模型的特点,设计的Viterbi 搜索路径如图7 所示.

图7 中每状态转移后的幸存路径以及搜索概率都只和前两个状态相关,这样就可以通过设计一组寄存器来实现其算法功能.对于每个待测词语,只需要通过Viterbi 模块与多个关键词模板分别进行匹配,求解出与之匹配得分的关键词HMM模型,然后将该匹配概率与概率门限进行比较,如果大于概率门限,则该概率对应的关键词即为识别结果.
HMM模式匹配过程包含了四个并行工作的Viterbi 状态搜索模块,通过比较器计算产生终结果并通过外设输出.本文外设采用LED 灯输出,LED[3]表示“杭州”,LED[2]表示“深圳”,LED[1]表示“北京”,LED[0]表示“广州”.由于LED灯是低电平驱动,所以值为0 的位代表识别结果,如果四个LED灯均为1,说明被检测词非关键词.
在XST 中对HMM模块进行综合,得到逻辑资源和时序结果如表4 所示.

显然,该模块采用并行匹配多个HMM模板,延迟时间较短,体现了硬件电路并行的优势.
版权与免责声明
凡本网注明“出处:维库电子市场网”的所有作品,版权均属于维库电子市场网,转载请必须注明维库电子市场网,https://www.dzsc.com,违反者本网将追究相关法律责任。
本网转载并注明自其它出处的作品,目的在于传递更多信息,并不代表本网赞同其观点或证实其内容的真实性,不承担此类作品侵权行为的直接责任及连带责任。其他媒体、网站或个人从本网转载时,必须保留本网注明的作品出处,并自负版权等法律责任。
如涉及作品内容、版权等问题,请在作品发表之日起一周内与本网联系,否则视为放弃相关权利。
- 详细介绍8种最常用的排序算法2024/10/28 17:17:12
- 异步的八种实现方式2024/9/29 17:13:56
- 谐波的危害有哪些2024/9/27 17:24:22
- 氩弧焊与电焊的优缺点,哪个更加结实2024/9/12 17:23:49
- 回调函数(callback)是什么?回调函数的实现方法2024/9/10 17:36:25



