一种基于关键词的回复生成方法与流程
本发明涉及计算机人工智能领域聊天机器人(也称人机对话系统)的回复生成领域,具体涉及基于关键词的回复生成方法。
背景技术:
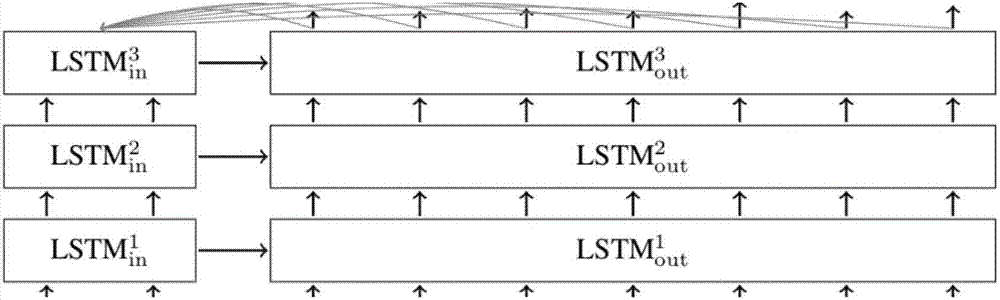
:聊天机器人是一种利用自然语言处理技术来模拟人类交流并和人类进行对话的计算机程序。聊天机器人的起源最早可以追溯到1950年图灵在《mind》上发表的文章《computingmachineryandintelligence》,该文提出了经典的“图灵测试”(turingtest),这一测试数十年来一直被视为计算机人工智能的终极目标。在聊天机器人中,回复生成是一个核心模块。近年来,使用神经网络的回复生成方式日益引起人们的兴趣。基于lstm的序列到序列(seq2seq)模型是一类神经网络生成模型,能够最大化给定的先前对话回合的生成概率。该方法使得连续对话回合之间构成了一一映射的关系。类似的模型比如,基于神经网络机器翻译nmt的对话模型。正如seq2seq模型的名称一样,这一模型用于将一个序列映射为另一个序列,广泛应用于目前的开放域聊天机器人、机器翻译、句法分析、问答系统等场景中,其基本结构如图1所示。seq2seq模型采用了一种encoder-decoder的框架,这一框架可以看作是一种文本处理领域的研究模式。对于句子对<i,o>,模型的目标是给定输入句子i,希望通过encoder-decoder框架来生成目标句子o。i和o可以是同一种语言(比如问答和聊天),也可以是两种不同的语言(比如机器翻译)。i和o都是由单词序列构成,假设i=<i1,i2,...im>以及o=<o1,o2,...on>,encoder顾名思义就是对输入句子x进行编码,将输入句子通过非线性变换转化为中间语义表示c:c=f(i1,i2…im)对于解码器decoder来说,其任务是根据句子x的中间语义表示c和之前已经生成的历史信息来生成i时刻要生成的单词oi:每个输出字符o都依次这么产生,那么整个系统就根据输入句子i生成了目标句子o。使用seq2seq模型构建聊天机器人,可以进行以下的建模:对于上文提到的<i,o>对中,使用i建模用户输入语句,使用o建模聊天机器人的回复语句。其含义是当用户输入message后,经过encoder-decoder框架计算,首先由encoder对message进行编码,形成中间语义表示c;decoder根据中间语义表示c生成聊天机器人的回复语句。这样,用户输入不同的message,聊天机器人生成与之对应的新的回复,这样就构成了一个实际的对话系统。将seq2seq模型应用于聊天机器人的场景时,encoder和decoder的结构单元通常都采用rnn,rnn模型对于文本这种线性序列来说是最常用的深度学习模型;现在使用更多的则是rnn的改进模型lstm模型和gru模型:这两种模型处理句子比较长的情形时效果要明显优于传统rnn模型。同时,为了提升模型效果,如图2所示,现在经常使用多层的seq2seq网络。但是目前的回复生成技术普遍存在着模糊回复的问题:模型倾向于生成一般性万能回复,比如“idon’tknow”,“me,too”等。lietal.2015提出了使用最大互信息损失代替交叉熵损失的方法,serbanetal.2016在生成过程中引入了一个随机变量。vladserbanetal.2016提出了通过一个关键词子模型增强关键词信息的隐式的关键词方法,mouetal.2016提出了首先生成一个关键词再由关键词正向反向生成回复剩余部分的方法。之前已有的单关键词技术要求有且只有一个关键词,但是不同回复的关键词个数不定,因此存在问题;而多关键词方法由于多个关键词信息被压缩,因此不能保证关键词显式出现在最终回复中。技术实现要素:本发明的目的是为了解决现有方法存在灵活性差、容易产生语意损失,以及序列对序列模型倾向于生成一般性万能回复的问题,而提出一种基于关键词的回复生成方法。一种基于关键词的回复生成方法包括以下步骤:步骤一:根据输入的消息生成关键词;步骤二:以步骤一输入的消息和生成的关键词作为输入,进行解码。将步骤一输入的消息转化成上下文向量,将步骤一中生成的第一个关键词和上下文向量送入解码器得到预测结果,若得到的预测结果与第一个关键词一致,则将第二个关键词和上下文向量送入解码器;若得到的预测结果与第一个关键词不一致,则仍将第一个关键词和上下文向量送入解码器,直至得到的预测结果与第一个关键词一致后,再将第二个关键词和上下文向量送入解码器,直至所有关键词按顺序送入解码器,并得到预测结果。本发明的有益效果为:测试数据集方面,英文数据采用ubuntu(乌班图)数据集,来源于ubuntu聊天室,数据量达到了290w对;中文数据采用了微博数据集,其来源为新浪微博的微博及对应评论,数据量达到了110w对。评价标准方面,自动评价使用了embeddingmetrics(词嵌入矩阵),包括进行meanpouring(平均池化)的average(平均)方法,考虑对齐信息的greedy(贪婪)方法,以及maxpouring(最大池化)的extrema(极大)方法。主动评价结果如下表:人工评价方面,使用0表示有语法错误,不流畅;+1表示依赖于场景;+2表示无语法,流畅性问题,独立于场景。对ubuntu数据集,不考虑专业性上的正确性。人工评价结果如下表所示:附图说明图1为seq2seq基本结构图;图中a、b、c、w、x、y、z表示词语,<go>表示开始符号,<eos>表示结束符号;图2为多层seq2seq模型图;lstm为长短期记忆网络,in为输入,out为输出;1,2,3:表示网络第1,2,3层;图3为关键词转移规则示意图;eos为结束字符;图4为本发明模型整体结构示意图;owi为第i个字符的词嵌入向量,pwi为第i个词被预测的概率,|v|为词表的大小。具体实施方式具体实施方式一:如图3和图4所示,一种基于关键词的回复生成方法包括以下步骤:步骤一:根据输入的消息生成若干个关键词;步骤二:以步骤一输入的消息和生成的关键词作为输入,进行解码。将步骤一输入的消息转化成上下文向量,将步骤一中生成的第一个关键词和上下文向量送入解码器得到预测结果,若得到的预测结果与第一个关键词一致,则将第二个关键词和上下文向量送入解码器;若得到的预测结果与第一个关键词不一致,则仍将第一个关键词和上下文向量送入解码器,直至得到的预测结果与第一个关键词一致后,再将第二个关键词和上下文向量送入解码器,直至所有关键词按顺序送入解码器,并得到预测结果。下表给出本发明生成回复的例子:消息关键词回复一日不见,如三月兮三月桃花童话三月桃花已逝每日一乐,一秒变格格!衣服刚标哥这衣服真像我的超萌大眼睛法国小女孩讲故事法国女孩未来法国女孩好可爱请原谅我一生放荡不羁笑点低一生笑点人生注定孤独一生的笑点万能配色参考颜色造型有点颜色造型很美具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤一中根据输入的消息生成关键词具体分为两种情况(由于训练过程中存在着标准答案,而预测过程中不存在,因此根据所处的不同过程分为两种情况):第一种情况为在训练过程中,使用词性标注工具对标准答案进行词性标注,选取出标注结果中词性为名词的所有词作为关键词。第二种情况为是在预测过程中,为了保持与训练过程的一致性,将关键词的选取范围限定为解码器词表中的所有名词,将这些名词作为候选词。使用输入消息中的所有词计算出它们与每一个候选词的互信息(pmi)的值作为该候选词的得分。进一步选取出所有互信息值大于0的候选词,同时候选词的顺序按互信息的值从大到小排序。最终的关键词为上述筛选后的候选词的前nk个词,其中nk为人工设置的关键词上限超参数。其它步骤及参数与具体实施方式一相同。具体实施方式三:本实施方式与具体实施方式一或二不同的是:所述步骤二中关键词和上下文向量送入解码器得到预测结果通过以下公式实现:本发明的另一个核心是引入了keywordgatingfunction(关键词函数):为现有gate(门)加入了关键词的embedding(词嵌入)信息,添加了一个关键词gate,以及修改了新记忆计算方式如下:zi=σ(wzeyi+uzsi-1+czci+vztj)ri=σ(wreyi+ursi-1+crci+vrtj)ki=σ(wkeyi+uksi-1+ckci+vktj)其中zi为更新门,σ为非线性激活函数,wz、uz、cz、vz、wr、ur、cr、vr、wk、uk、ck、vk、e、u、c、v为可学习参数,e为词向量矩阵,yi为i时刻预测结果的独热表示,si-1为第i-1时刻解码器隐层状态向量,ci为i时刻的上下文向量(用来表示输入的消息),tj为第j个关键词的独热表示,ri为忘记门,ki为关键词门,为i时刻的新记忆向量,为按向量元素逐个相乘,tanh为激活函数。本发明模型整体结构如图4所示。其它步骤及参数与具体实施方式一或二相同。具体实施方式四:一种基于关键词的回复生成方法的应用,将所述方法应用于计算机人工智能聊天机器人的人机对话系统中基于关键词的回复生成过程。采用以下实施例验证本发明的有益效果:实施例一:本发明可以直接应用于开放域的聊天机器人系统中,是一个聊天机器人的核心模块。本发明的应用载体是哈尔滨工业大学社会计算与信息检索研究中心开发的聊天机器人“笨笨”。首先,该模块根据输入预测出若干个关键词,然后该模块结合输入与关键词共同解码出一句回复,完成一次基于关键词的回复生成任务。从部署方式上来讲,本发明可以独立作为一个计算节点,部署于阿里云或者美团云等云计算平台上,与其它模块之间的通讯可以通过绑定ip地址和端口号的方式进行。本发明的具体实现上,因为使用了深度学习相关技术,所以需要使用相应的深度学习框架:本技术的相关实验基于开源框架pytorch实现。如果有需要,可以换做其它框架,比如同样开源的tensorflow,或者企业内部使用的padlepadle等。本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1